4 метрики, которые мы отслеживаем для обеспечения бесперебойной работы многокомпонентной системы

4 метрики, которые мы отслеживаем для обеспечения бесперебойной работы многокомпонентной системы
В системе, которая ежедневно обслуживает тысячи пользователей неизбежно возникают ошибки. Чтобы быстро разбираться, что происходит с системой, не исследуя каждый отдельный случай, мы выделили несколько метрик, которые позволяют с первого взгляда оценить ситуацию в целом.
Предположим, одна и та же ошибка происходит 91 раз. В старой системе логирования, когда наша служба поддержки получала автоматически сгенерированное письмо, этот факт был триггером для начала исследования проблемы и поиска путей решения.
В новой системе мы построили график зависимости числа ошибок от количества пользователей, и можем сразу увидеть, что ошибка происходит 91 раз у 15 пользователей. Если число пользователей и число ошибок пошли вверх, это сигнализировало бы об общей проблеме. Но если число ошибок растет, а число устройств остается небольшим, значит проблема может быть в самих пользователях и их поведении в системе.
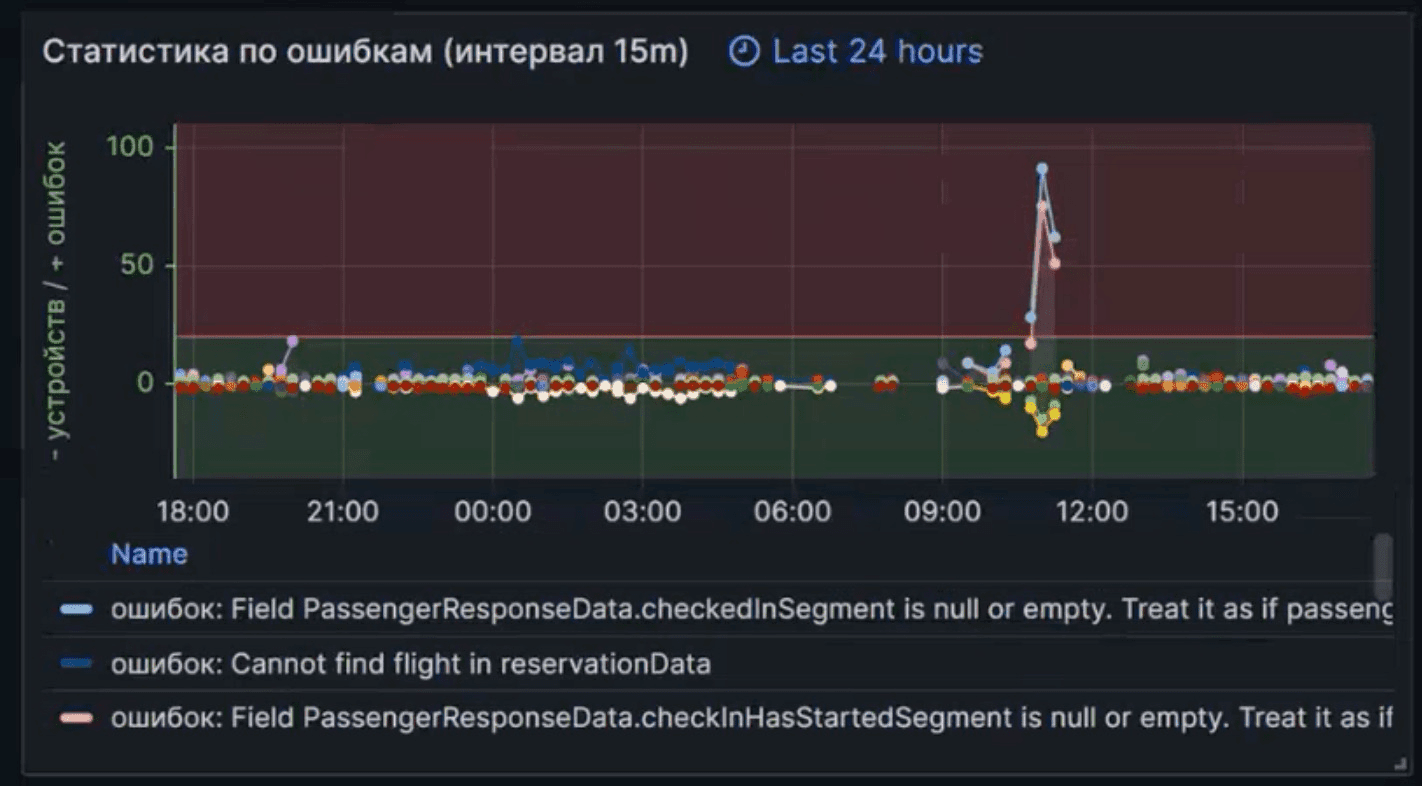 image1.png
image1.png
Если ошибка выглядит легитимно, затрагивает достаточное количество пользователей и воспроизводится, будет выпущен фикс. Чтобы быстро узнать, исправилась ли ситуация после запуска фикса, мы маркируем ее уникальным тегом и выводим график, отслеживающий случаи появления конкретной ошибки после запуска исправлений. Таким образом мы можем убедиться, что решение сработало и ошибка не воспроизводится.
Отдельный график показывает новые уникальные ошибки. Он позволяет быстро узнавать о возникновении новых проблем, особенно после запуска обновлений.
Таким образом, три графика позволяют быстро оценить ситуацию при возникновении ошибок и понять, какое вмешательство требуется со стороны службы технической поддержки.

